masymos-core
MaSyMoS Core - create and query the DB
attendees
- mp
- ms
discussion/problems
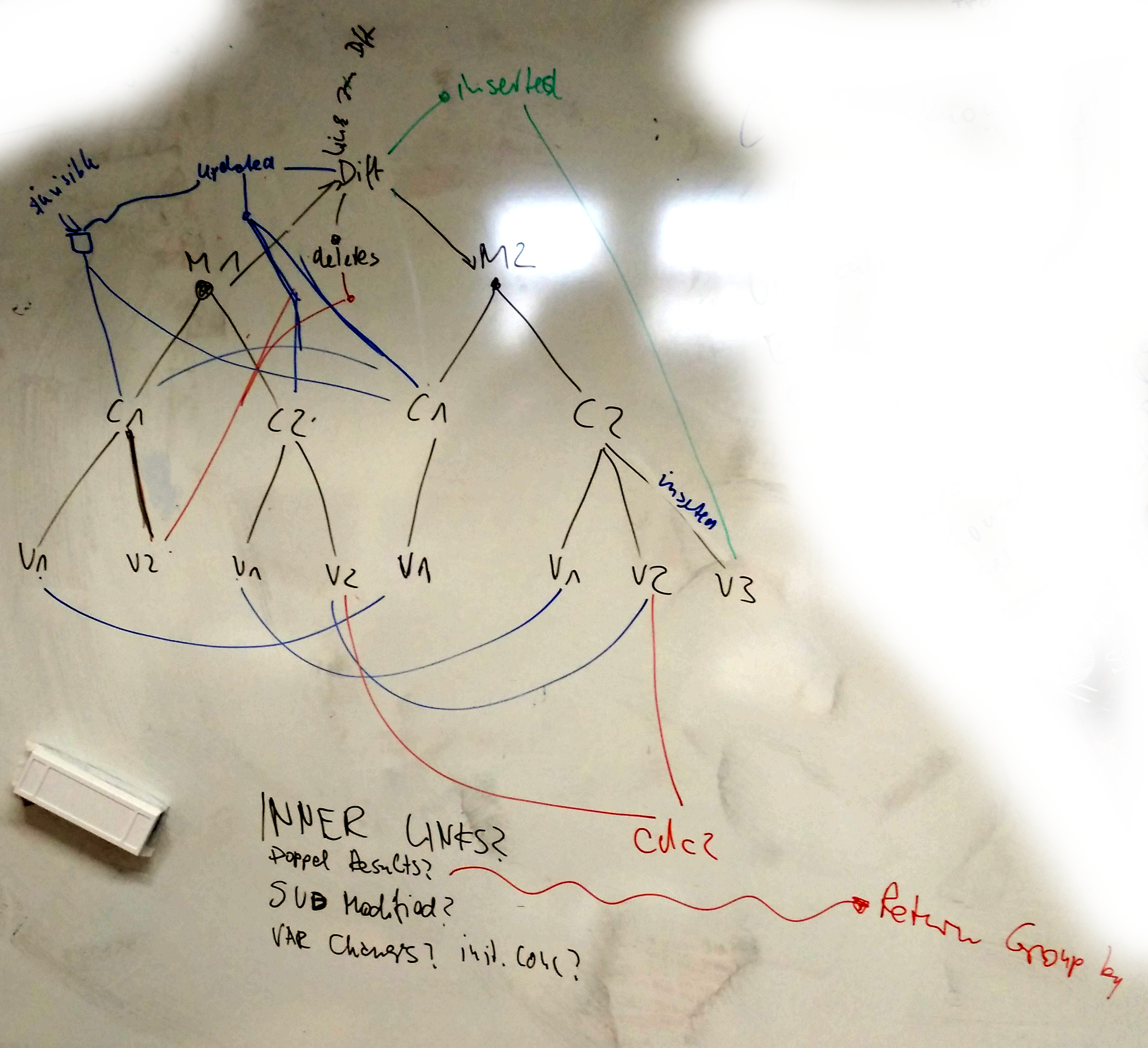
- immer gesamten grpah speichern? mit allen internals? macht ron ja gerade schon.. is das gut?
- pro:
- interne links
- changes of subsubsubnodes -> how to represent them?
- cons:
- gibt redundante suchergebnisse…
- models are connect through diff knoten
- diff node enthaelt infos zu diff document usw. (wie andere dokument knoten)
- diff node hat sub nodes: inserted/updated/deleted
- alle haben unterknoten die knoten in model version1 und version2 verbinden
- plus detailed changes about diff?
- plus ontology terms related to the diff
- updated knoten hat besondere unterknoten:
- invisible(?) -> etwas hat sich geaendert, was in der graph db nicht representiert wurde
- moved
- diff generation as background-task
- redundancy in cases of error
- don’t touch ron’s stuff -> just add additional plugin?
- search for
M1 -[has_ancestor]-> M2` without `M1 -> :DIFF -> M2und erzeuge diff und den ganzen bunten kram aus dem anhang..
redundante suchergebnisse?
- wenn wir alles doppelt speichern werden bei suchen natuerlich alle versionen returned…
- koennen dann aber ge-grouped-by-ed werden? ist vielleicht sowieso besser? ansonsten: will man immer die latest version haben?
open questions
- difference between URI und XMLDOC in doc node von db?
- where to insert the code in masymos?
- how to represent diff ontology in db? should we link our diff nodes to the ontology? how is that done for cdc2?